记录一次Playwright的使用
Playwright介绍
Playwright,微软旗下的开源自动化测试框架
来自知乎用户
Playwright是一个强大的Python库,仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作,并同时支持以无头模式、有头模式运行。
Playwright提供的自动化技术是绿色的、功能强大、可靠且快速,支持Linux、Mac以及Windows操作系统。
官方标语:
Playwright enables reliable end-to-end testing for modern web apps.
Any browser • Any platform • One API
在这次简短上手后立马转用此库,非常的强大好用
安装
pip install playwright
安装完毕后,安装浏览器环境:
python -m playwright install
即可开始使用
方便的录制功能
安装完毕后,使用以下指令即可启动浏览器录制,会自动生成对应代码
python -m playwright codegen
python -m playwright codegen --help
Usage: index codegen [options] [url]
open page and generate code for user actions
Options:
-o, --output <file name> saves the generated script to a file
--target <language> language to use, one of javascript, python, python-async, csharp (default: "python")
-h, --help display help for command
Examples:
$ codegen
$ codegen --target=python
$ -b webkit codegen https://example.com
使用
起因
事情起因朋友需要爬取前程无忧招聘网站下全国主播的招聘信息,第一想到的是API爬取,结果在尝试逆向加密参数type__1458时,遇到大量混淆,无力破解,遂放弃并打算使用自动化测试框架抓取网页源码后使用BS4解析方式来曲线救国
计划
因为总共有200页,每页50条,这里计划Playwright爬取每页代码,然后存入MongoDB数据库,等待后续Beautifulsoup4解析(防止解析代码出问题需要重新多次获取网页导致反爬,减少被反爬次数),解析后的结果需要汇总成一张EXCEL表格,因此同理将解析结果存入数据库待提取汇总。所以全程便是:
- Playwright爬取网页-源码并存入数据库
- Beautifulsoup4解析网页,将结果格式化并存入数据库
- 从数据库提取格式化后的结果,汇总进一张EXCEL表格
爬取网页
由于工具新出,网上教程较少,这里使用录制功能先观察观察:
python -m playwright codegen --target python -o 'get_page.py' -b chromium https://search.51job.com/list/000000,000000,0000,00,9,99,%E4%B8%BB%E6%92%AD,2,1.html
根据需求和观察生成结果后,最终代码如下:
# get_page.py
import time
from playwright.sync_api import Playwright, sync_playwright
from db import MongoFunc
# 用于判断页面是否正常获取
# 如果被反爬则为False,用于触发阻塞
IS_PAGE_NORMAL = True
def run(playwright: Playwright) -> None:
global IS_PAGE_NORMAL
global NOW_PAGE
mongodb = MongoFunc()
# 这里为指定不同的浏览器,这里使用的是firefox
# browser = playwright.chromium.launch(headless=False)
browser = playwright.firefox.launch(headless=False)
context = browser.new_context()
page = context.new_page()
while True:
next_page_index = mongodb.get_next_index()
if next_page_index == 0:
# 已经全部获取完毕
break
next_page_url = f"https://search.51job.com/list/000000,000000,0000,00,9,99,%25E4%25B8%25BB%25E6%2592%25AD,2,{next_page_index}.html?lang=c"
# 跳转指定URL地址
page.goto(next_page_url)
#page.get_by_role("listitem").filter(has_text=str(NOW_PAGE)).locator("a").click()
# 等待页面渲染完毕
page.wait_for_load_state('networkidle')
if '滑动验证页面' in page.content():
# 触发反爬
IS_PAGE_NORMAL = False
input('WAIT TO PASS')
page.wait_for_load_state('networkidle')
mongodb.insert_html(page.content(),next_page_index)
time.sleep(3)
# ---------------------
context.close()
browser.close()
if __name__ == '__main__':
with sync_playwright() as playwright:
run(playwright)
数据库:
import pymongo.errors
from pymongo import MongoClient
class MongoFunc:
def __init__(self, max_pages=200):
self.client = MongoClient(host='127.0.0.1', port=27018)
self.db = self.client['51job']
# FOR HTML INSERT
self.statuc_c = self.db['pages_load_status']
self.html_c = self.db['pages']
# FOR JSON MAKER
self.json_stats_c = self.db['data_status']
self.json_c = self.db['data']
self.INIT_MAX_PAGES = max_pages
self.__check_init()
def __check_init(self):
now_pages_status = self.statuc_c.find_one()
if not now_pages_status['unloaded'] and not now_pages_status['loaded']:
self.statuc_c.update_one(now_pages_status, {'$set': {'unloaded': [i for i in range(1, 201)]}})
def update_to_loaded(self, index: int):
now_pages_status = self.statuc_c.find_one()
unloaded = now_pages_status['unloaded'].copy()
loaded = now_pages_status['loaded'].copy()
unloaded.remove(index)
loaded.append(index)
loaded.sort()
self.statuc_c.update_many(now_pages_status, {'$set': {'unloaded': unloaded, 'loaded': loaded}})
def get_next_index(self) -> int:
# 在数据库中,保存着unloaded和loaded两数组,用来防止重复获取和间断获取功能实现
now_pages_status = self.statuc_c.find_one()
unloaded = now_pages_status['unloaded']
try:
return unloaded[0]
except IndexError:
return 0
def insert_html(self, content: str, index: int):
# 向数据库中插入网页源码
try:
self.html_c.insert_one({"_id": index, "content": content})
self.update_to_loaded(index)
except pymongo.errors.DuplicateKeyError:
# 此ID重复,即PAGE重复
self.update_to_loaded(index)
def update_data_index(self, index: int):
loaded_index = self.json_stats_c.find_one()
self.json_stats_c.update_one(loaded_index, {"$set":{"loaded_index": index}})
def get_loaded_data_index(self) -> int:
# 和get_next_index同理,不过数据库中仅仅保存int型loaded_index,如果已经用BS4解析完毕并存入数据库,就加1,因此解析是按页码顺序来,为什么不采用上面方法,算是改进吧...
loaded_index = self.json_stats_c.find_one()
return loaded_index['loaded_index']
def get_page_content(self,page_id:int) -> str:
# 获取已存储的网页源码
page_json = self.html_c.find_one({"_id":page_id})
return page_json['content']
def insert_data_json(self,info:dict,index:int) -> None:
# 将解析完毕的数据存入数据库
try:
self.json_c.insert_one(info)
self.update_data_index(index)
except pymongo.errors.DuplicateKeyError:
# 重复
self.update_data_index(index)
最终爬取结果:
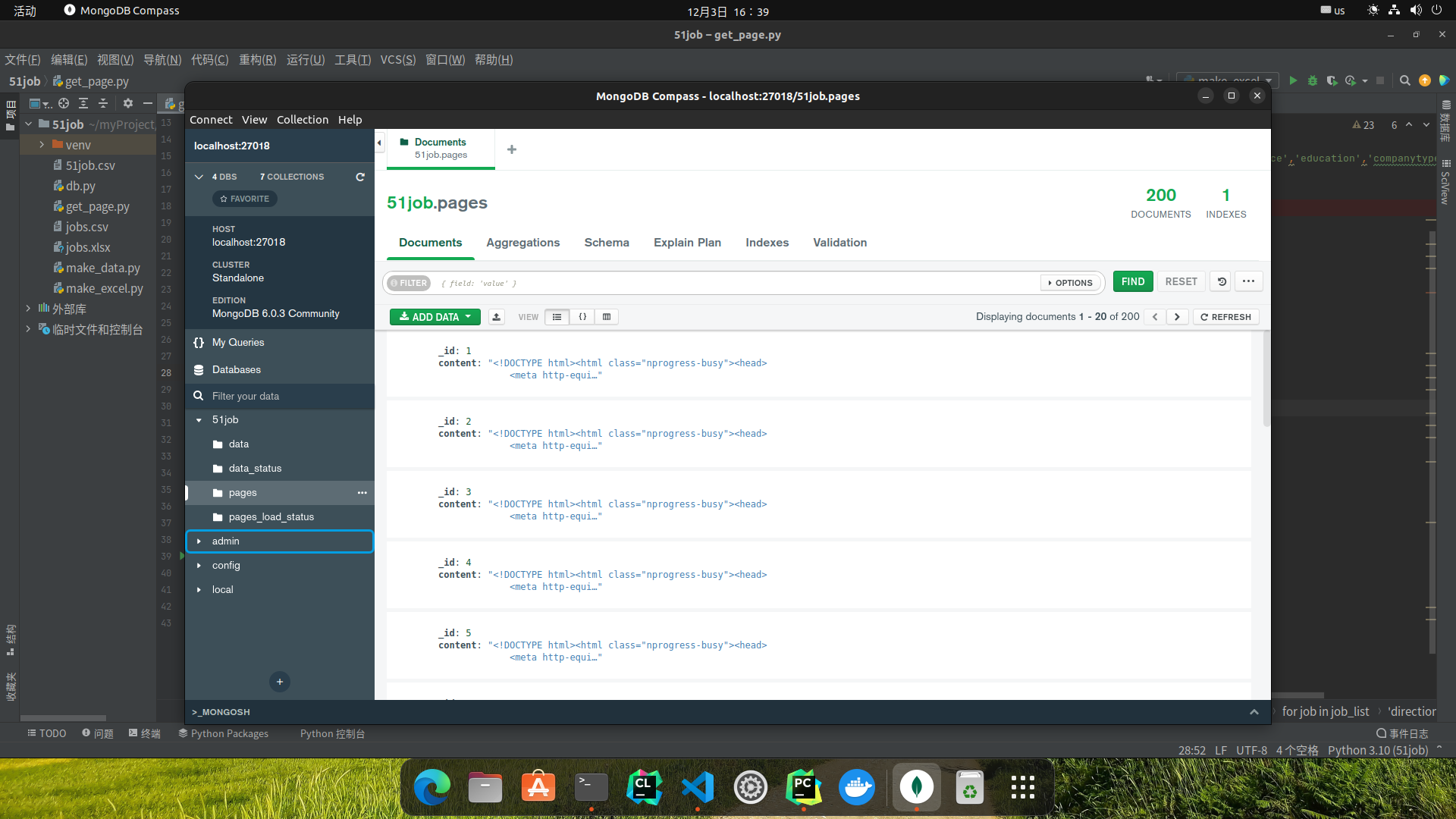
不得不说Playwright是真的顶,完全自动,甚至不影响电脑的正常使用,不需要丢掉鼠标键盘,全程自动,且非常快速。
中间遭遇几次反爬,脚本会自动停止,使用input()阻塞,过滑块后,任意字符回车即可。
解析源码
解析数据这块,惊喜发现,网站程序员把API获取到的JSON数据写进了源码,这下解析都不用费多大功夫:
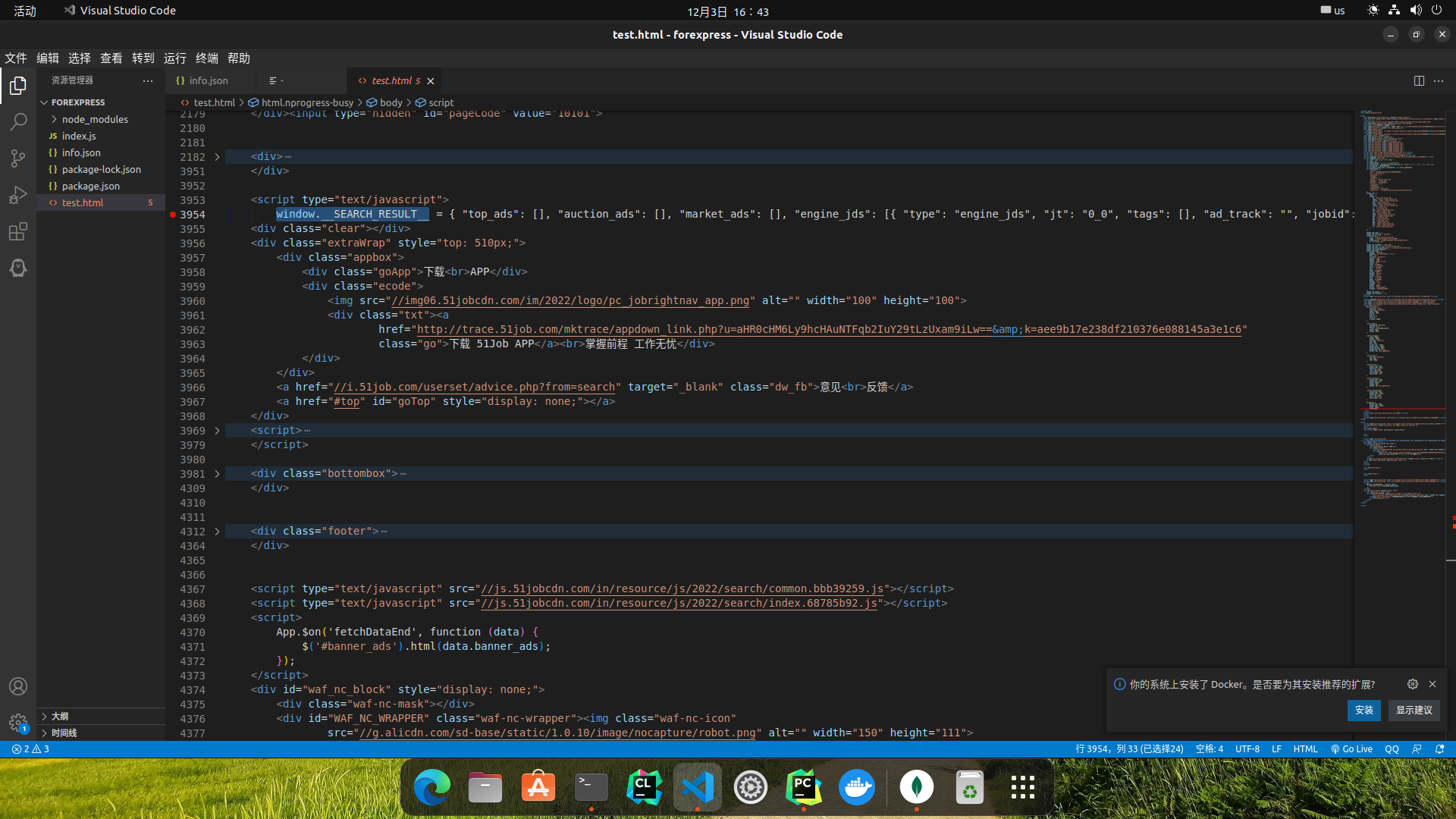
最终解析代码:
# make_data.py
from db import MongoFunc
from bs4 import BeautifulSoup,SoupStrainer
import json
mongodb = MongoFunc()
def run():
while True:
try:
json_data = {}
now_index = mongodb.get_loaded_data_index()+1
html_content = mongodb.get_page_content(now_index)
# 仅截取body元素
only_body = SoupStrainer('body')
soup = BeautifulSoup(html_content,'lxml',parse_only=only_body)
script_tags_list = soup.find_all('script')
for script_tag in script_tags_list:
if 'SEARCH_RESULT' in script_tag.text:
json_content = script_tag.text
json_content = json_content.replace('\n','')
json_content = json_content.replace('window.__SEARCH_RESULT__ =','')
json_data = json.loads(json_content)
break
# 存入数据库
mongodb.insert_data_json({"_id":now_index,"jobs":json_data['engine_jds']},now_index)
except TypeError:
print('ALL DONE')
break
if __name__ == '__main__':
run()
最终成果:
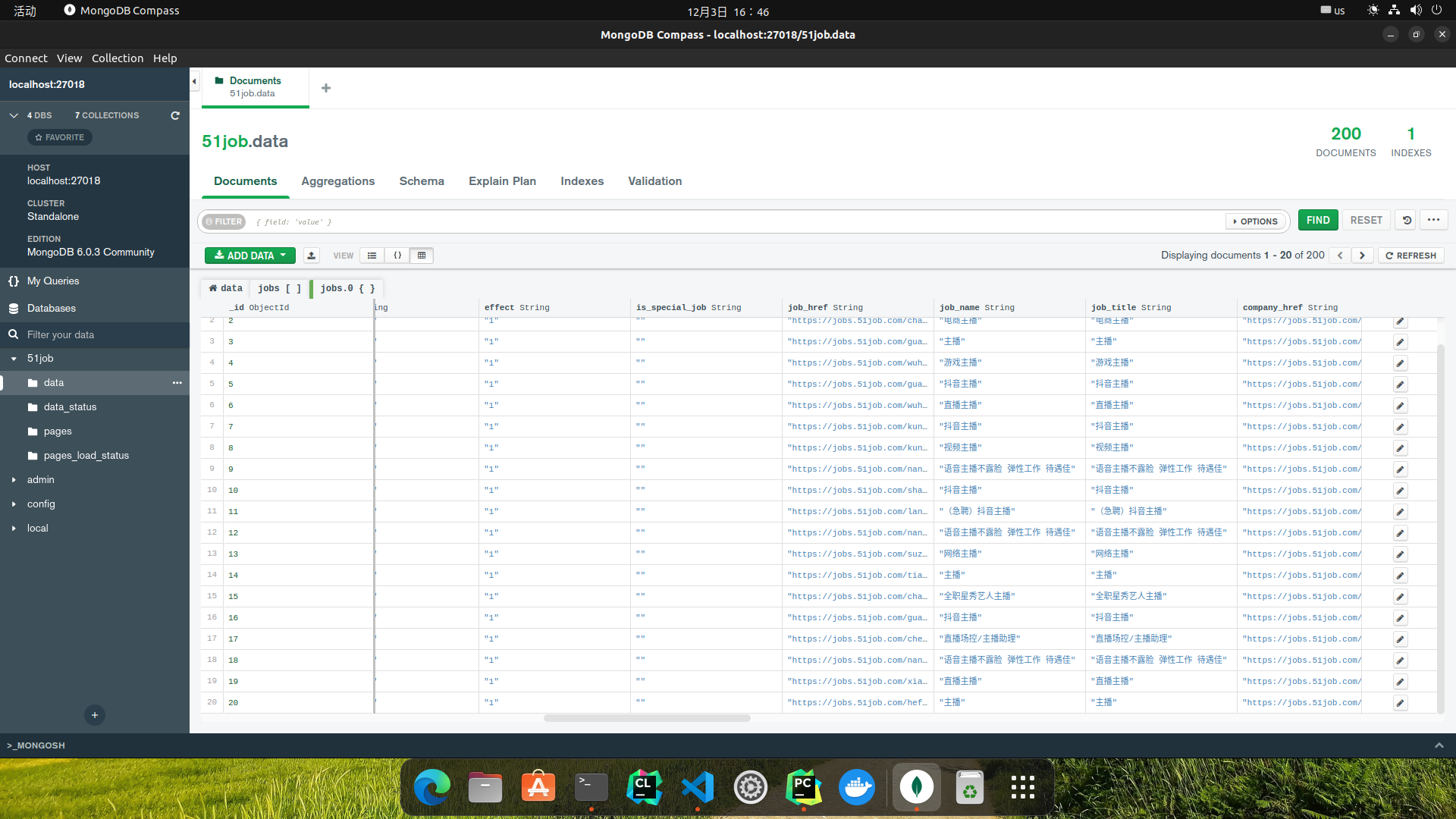
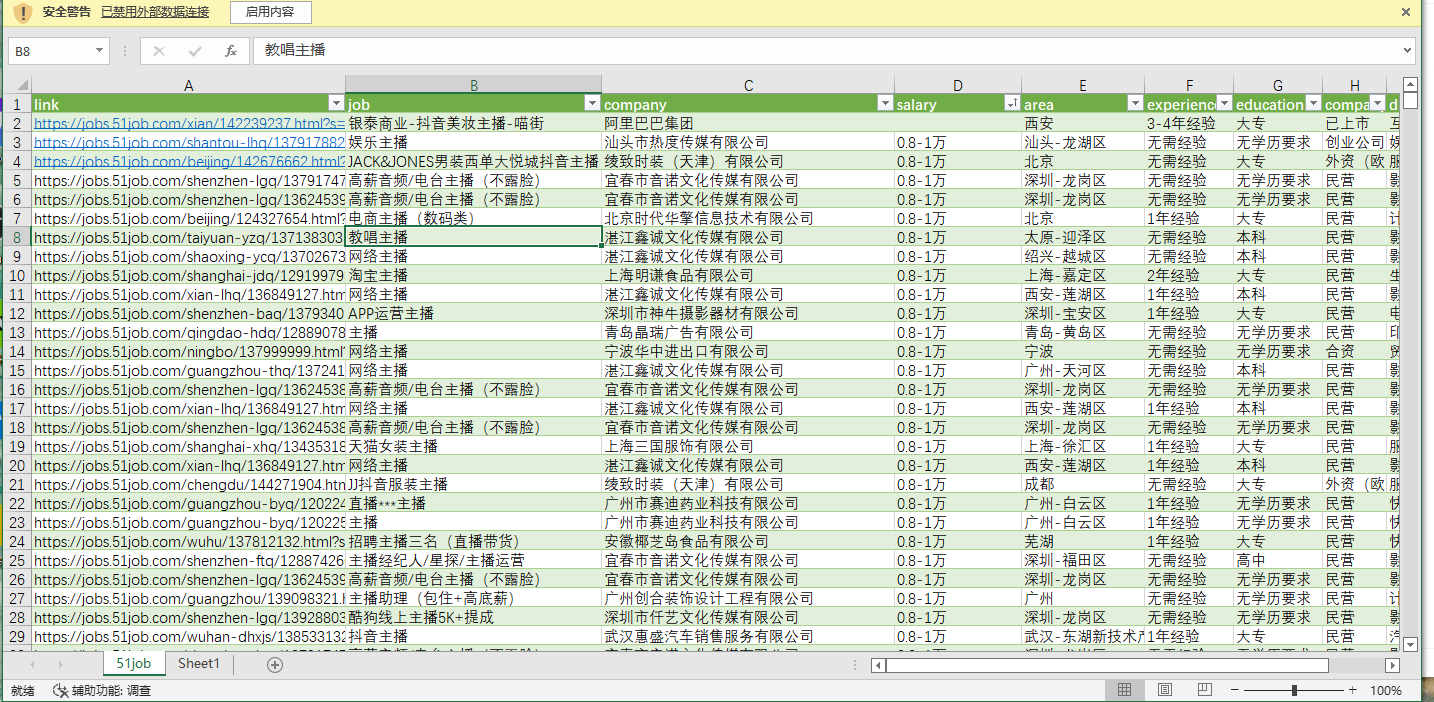
汇总表格
汇总成表格时犯了难,预想的是XLS或XLSX格式,但是搜索现有的库后发现都是不会的,再学需要时间成本,这时我想到之前使用过的CSV格式,写入非常简单,并且也可以用EXCEL打开,所以先用CSV格式看看效果:
# make_excel.py
import csv
from db import MongoFunc
def run():
mongodb = MongoFunc()
with open('51job.csv', 'w+', newline='') as f:
# 表头,需要与下面字典Key值对应
csv_header = ['link', 'job', 'company', 'salary', 'area', 'experience', 'education', 'companytype', 'direction']
csv_writer = csv.DictWriter(f, csv_header)
# 表头写入
csv_writer.writeheader()
for data in mongodb.json_c.find():
job_list = data['jobs']
for job in job_list:
data_dict = {
'link': job['job_href'],
'job': job['job_name'],
'company': job['company_name'],
'salary': job['providesalary_text'],
'area': job['workarea_text'],
'experience': '',
'education': '',
'companytype': job['companytype_text'],
'direction': job['companyind_text'],
}
# 这里是因为job['attribute_text']为列表,最长长度3,最低长度1,经验和学历要求不一定有
if len(job['attribute_text']) < 2:
data_dict['experience'] = '无经验要求'
else:
data_dict['experience'] = job['attribute_text'][1]
if len(job['attribute_text']) < 3:
data_dict['education'] = '无学历要求'
else:
data_dict['education'] = job['attribute_text'][-1]
csv_writer.writerow(data_dict)
print('ALL DONE')
if __name__ == '__main__':
run()
最终成果:
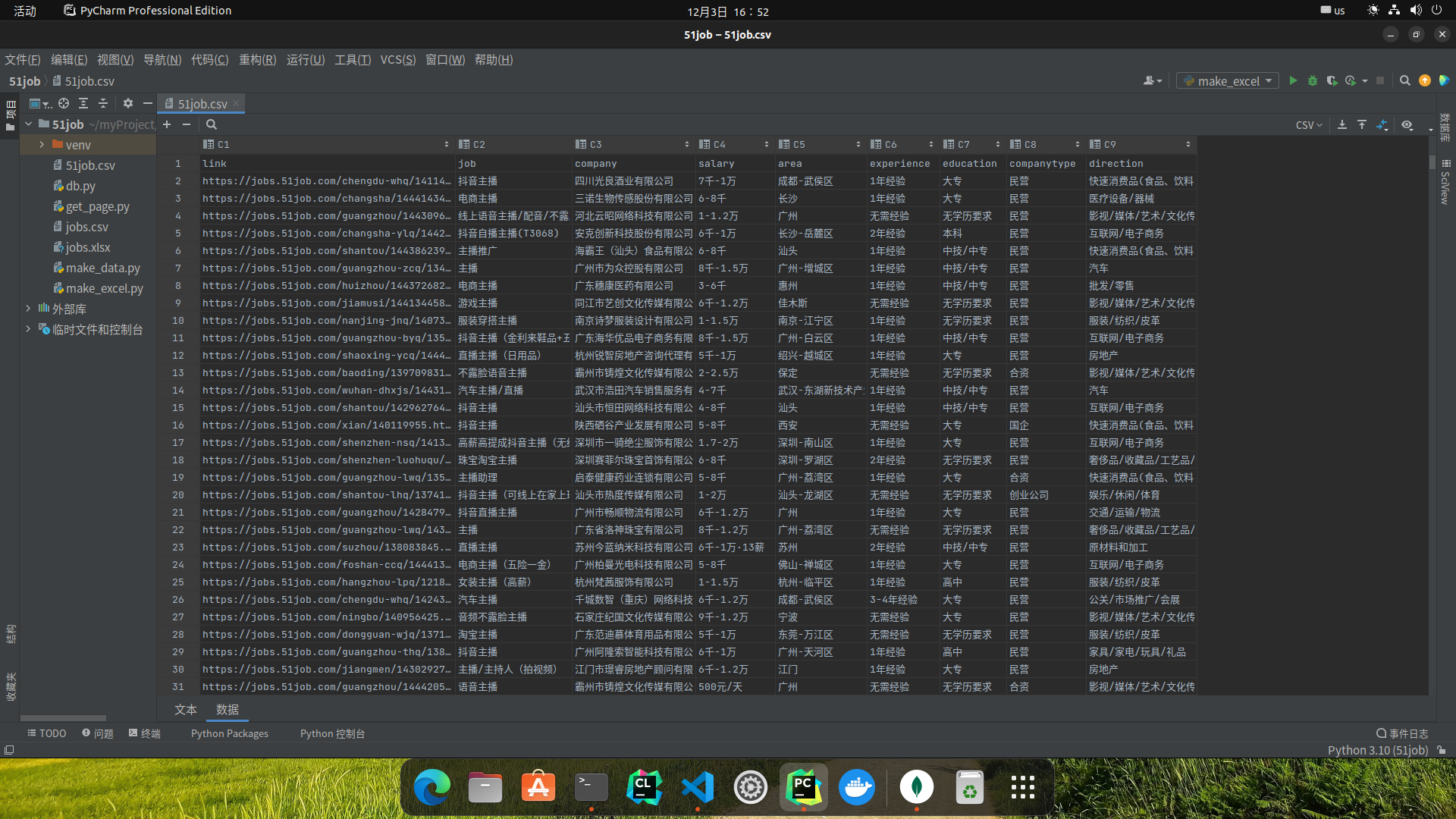
结果发现在EXCEL中打开会因编码问题乱码,后来使用以下方式解决:
数据-从文本/CSV文件 导入数据
稍微处理过后最终成果,甚至可以保存为XLSX格式: