Scrapy爬虫框架初探
简介
An open source and collaborative framework for extracting the data you need from websites.
In a fast, simple, yet extensible way.
来自官网介绍
Scrapy是用纯Python实现的,抓取网页数据并提取结构性数据而编写的应用框架,用途广泛,用户只需要定制开发几个模块即可轻松实现爬虫。
架构图(以下皆来自RUNOOB-Scrapy 入门教程):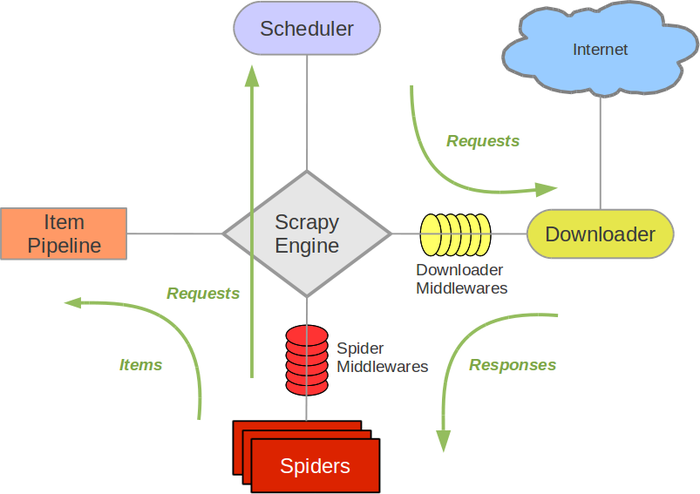
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
使用
安装:
|
安装完毕后,启动一个新项目
|
生成项目后,主要有以下文件:
scrapy.cfg: 项目的配置文件。
spiders/: 项目的Python模块,将会从这里引用代码。
spiders/items.py: 项目的目标文件。
spiders/pipelines.py: 项目的管道文件。
spiders/settings.py: 项目的设置文件。
spiders/spiders/: 存储爬虫代码目录。
实战
以 https://www.guazi.com/buy 中前80页数据为目标,先来分析网页
分析
可以找到数据为API传来: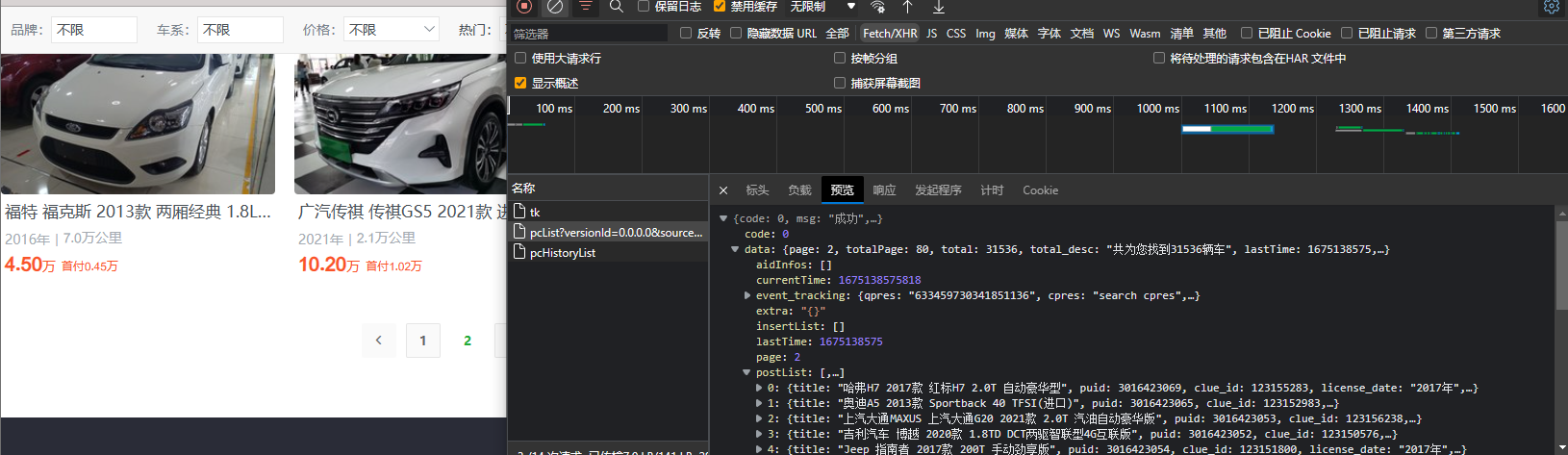
观察带的参数,还挺多,但都是空的,只有两个比较重要,一个是deviceId一个是qpres,deviceId基本可以写死,qpres则是随机生成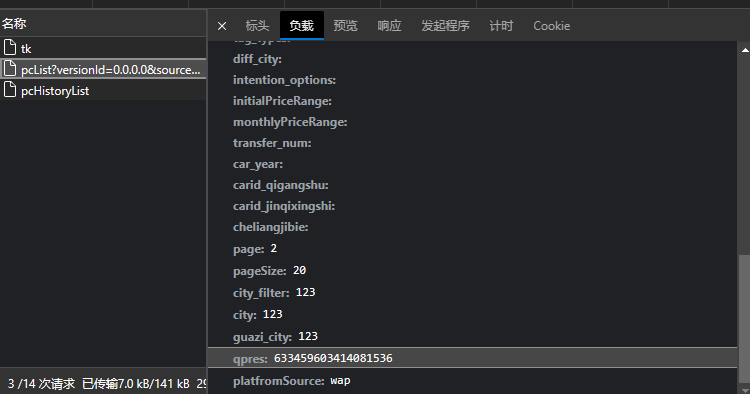
但是首页(第一页),没有携带qpres也爬取成功,所以不妨试试编辑重播,其它不改,只修改page参数来请求第二页,发现请求成功,那就不需要逆向了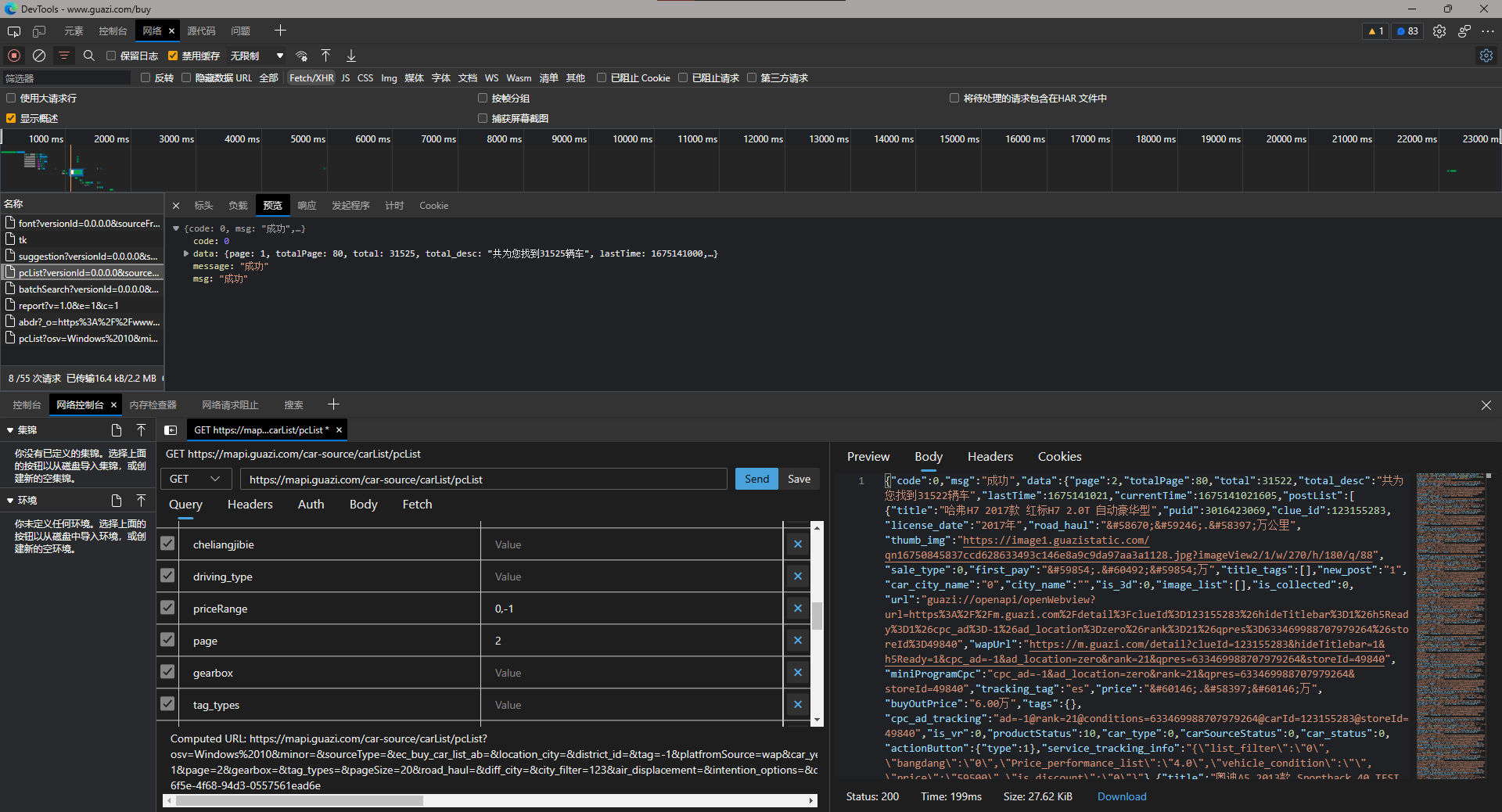
(其实qpres就来自于响应结果中)
同时观察其它参数,基本就是网页中的筛选条件,理论上去除也没事(甚至deviceId也可去除),根据爬取需求并结合多次测试,这里只取以下参数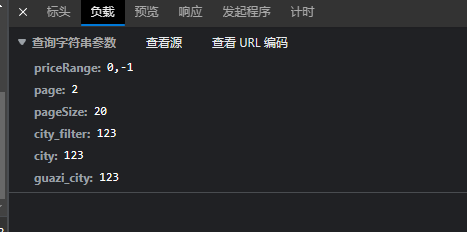
基本就涵盖了城市地区,价格区间(这里是不限制价格),以及页数和一页数据大小。
再来看Headers,发现竟然还有token之类的,继续重播看看,发现同样可以去掉,仅保留以下两个参数: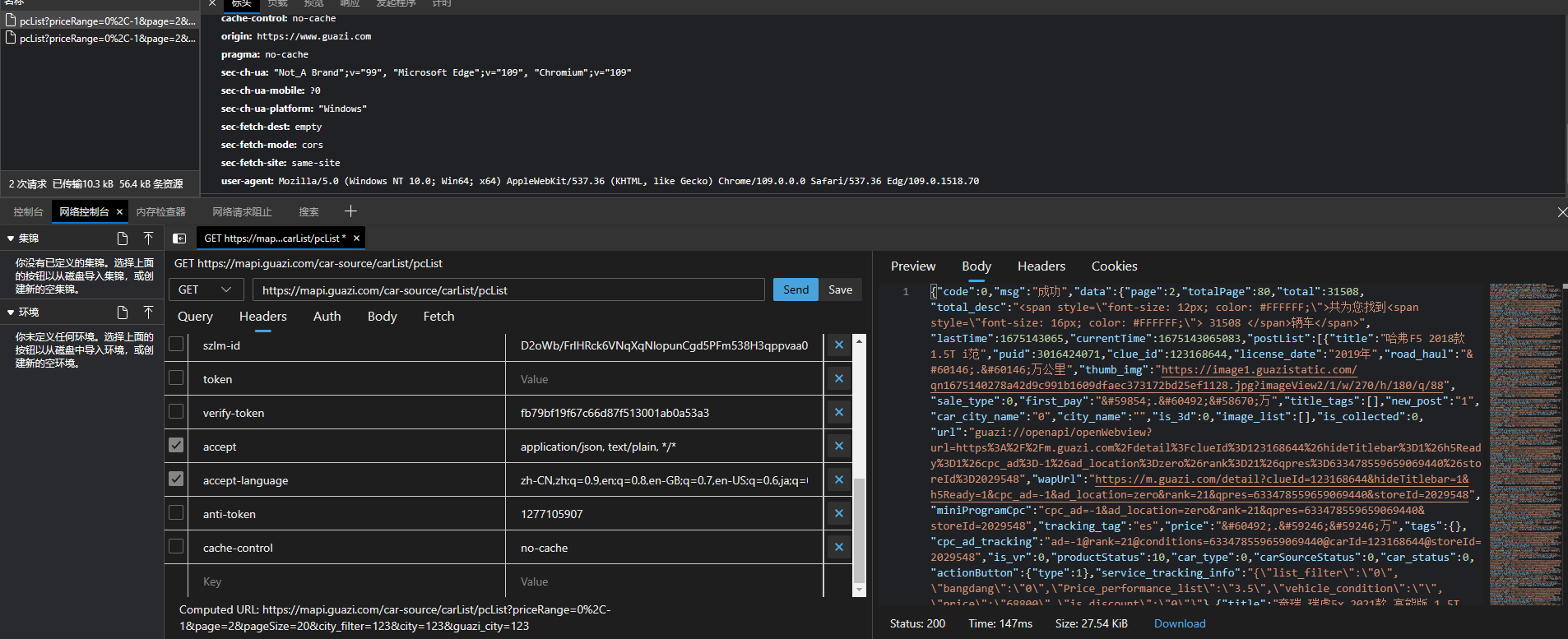
但是,这个网站有文本混淆(或者说文本加密)
字体加密处理
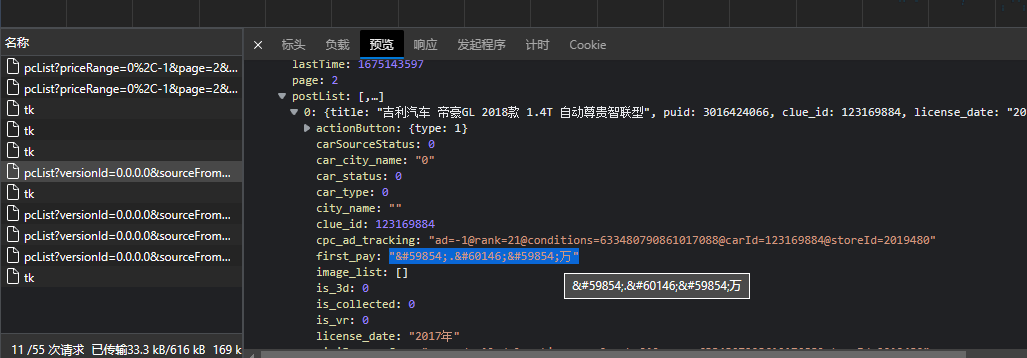
可以参考此位大佬的文章 字体加密破解
请求了两个字体,看着感觉像第一个,先下载第一个
打开在线 字体编辑器并导入
还可以使用fontTools导出字体的XML文件,使用以下指令安装
|
使用以下代码,保存XML:
|
可以看到映射其关系
但其实根据字体编辑器给与的信息和查询,可以发现其实并非是加密,而是在Unicode私用区定义,反正就10个数字,干脆自己手动弄一张映射表完事:
|
爬取数据
接下来可以准备开始爬取数据了
scrapy2.5中文文档
scrapy官方文档(英文)
前面已经准备好了Headers,可以直接写入settuing.py中的DEFAULT_REQUEST_HEADERS,这样就可以保证全局Headers。
再来定义一下,需要的数据字段(items.py):
|
